
Introduction
David Navon’s paper about the speed with which people process global and local information is extremely popular (Navon, 1977). The paper has been cited nearly 1,800 times (checked in the beginning of 2016).
The basic idea of Navon’s study is that when objects are arranged in groups, there are global features and local features. For example, a group of trees has local features (the individual trees) and the feature of a forest (the trees together).
The basic finding of Navon’s work is that people are faster in identifying features at the global than at the local level. This effect is also known as global precedence.
An example of a Navon figure is shown below. The figure has a global feature, it looks like an H. Its local feature are the many small letters X the figure is made of. People are typically quicker detecting an H than an X.
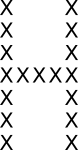
The global precedence effect is not just observed in this specific setup. For example, generally words are recognized quicker than its individual letters. Can you think of other examples?
Advertisement
Please note that the ad below is to support the PsyToolit platform. Clicking it helps us.
Above is an add. The rest below is ad free. Thank you for watching this.
About this implementation
This specific implementation is designed by PsyToolkit developer Gijsbert Stoet. There are 50 trials. On each trial, you get up to 4 seconds to decide whether you see a target letter (H or O) at the local or global level, or not. On each trial, you need to respond with a key press. There are clear instructions at the start on how to exactly respond, and there is feedback at the end. According to the theory, you should respond fastest (and made fewest mistakes) in the global condition.
| The distance between the screen and your eyes might influence how easy the global features can be detected. For example, if you sit very close to the screen, the local features will be more obvious that the global features. |
Run the demo
| In this example, you will see Navon types of letters. You will need to decide if a letter is or contains the letters H or O. If you an H or O, you press the b button. If you do not see an H or O, you press the n button (think n stands for no). |
Data output file
| In PsyToolkit, the data output file is simply a textfile. The save line of the PsyToolkit experiment script determines what is being saved in the data output file. Typically, for each experimental trial, you would have exactly one line in your text file, and each number/word on that line gives you the information you need for your data analysis, such as the condition, response speed, and whether an error was made. |
Meaning of the columns in the output datafile. You need this information for your data analysis.
| Colum | Meaning |
|---|---|
1 |
The letter. For example, Hs stands for a big H made of small letters S |
2 |
The level where the target is, or none if there is no target letter at all |
3 |
Same as column 2, but in numbers. 0: no target. 1: target at local level. 2: target at global level |
4 |
Status. 1: correct, 2: wrong response, 3: too slow |
5 |
Reaction time in milliseconds |
Check out the source code
Download
| If you have a PsyToolkit account, you can upload the zipfile directly to your PsyToolkit account. |
If you want to upload the zipfile into your PsyToolkit account, make sure the file is not automatically uncompressed (some browsers, especially Mac Safari, by default uncompress zip files). Read here how to easily deal with this.
Further reading
-
Navon, D. (1977). Forest before trees - Precedence of global features in visual-perception. Cognitive Psychology, 9, 353-383.
-
Navon, D. (2003). What does a compound letter tell the psychologist’s mind? Acta Psychologica, 114, 273-309.